| time | topic |
|---|---|
| 3:00-3:45 | Understanding clusters in data using visualisation |
| 3:45-4:30 | Building better classification models with visual input |
Visualising High-dimensional Data with R
What are clusters?
Ideal thinking of neatly separated clusters, but it is rarely encountered in data
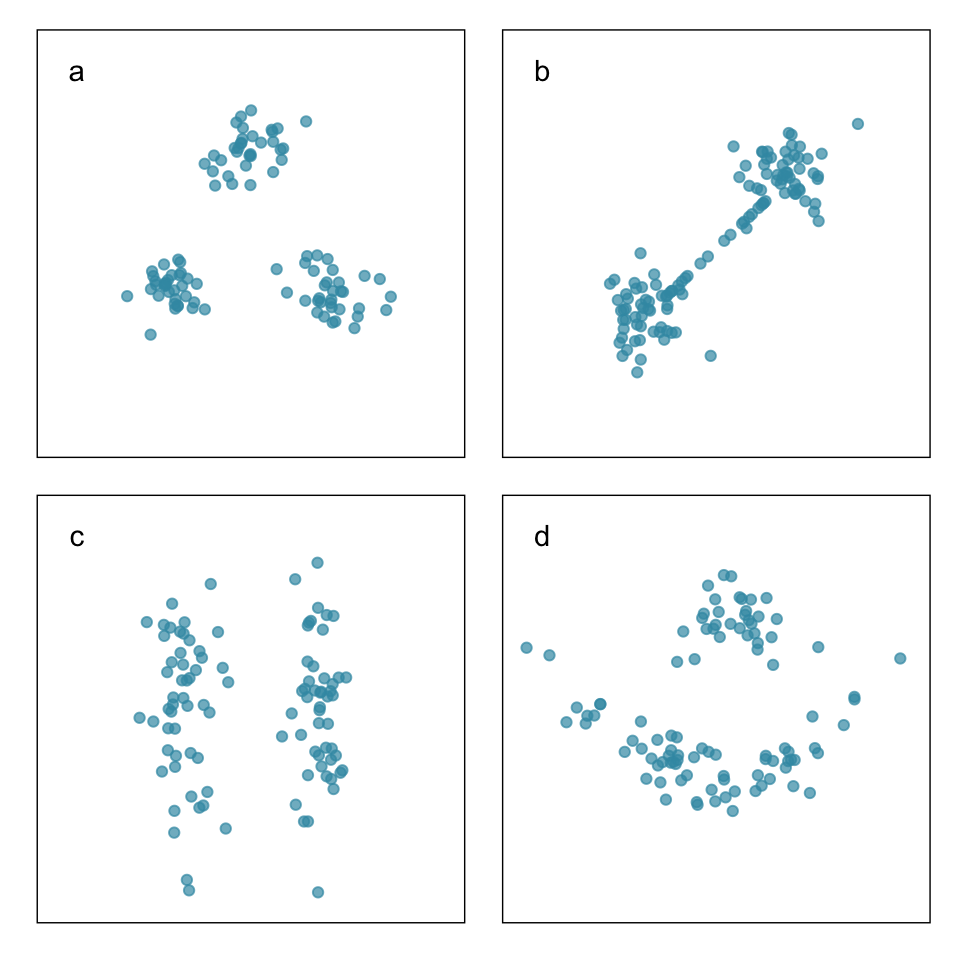
Objective is to organize the cases into groups that are similar in some way. You need a measure of similarity (or distance).
Why visualise? Which is the better?
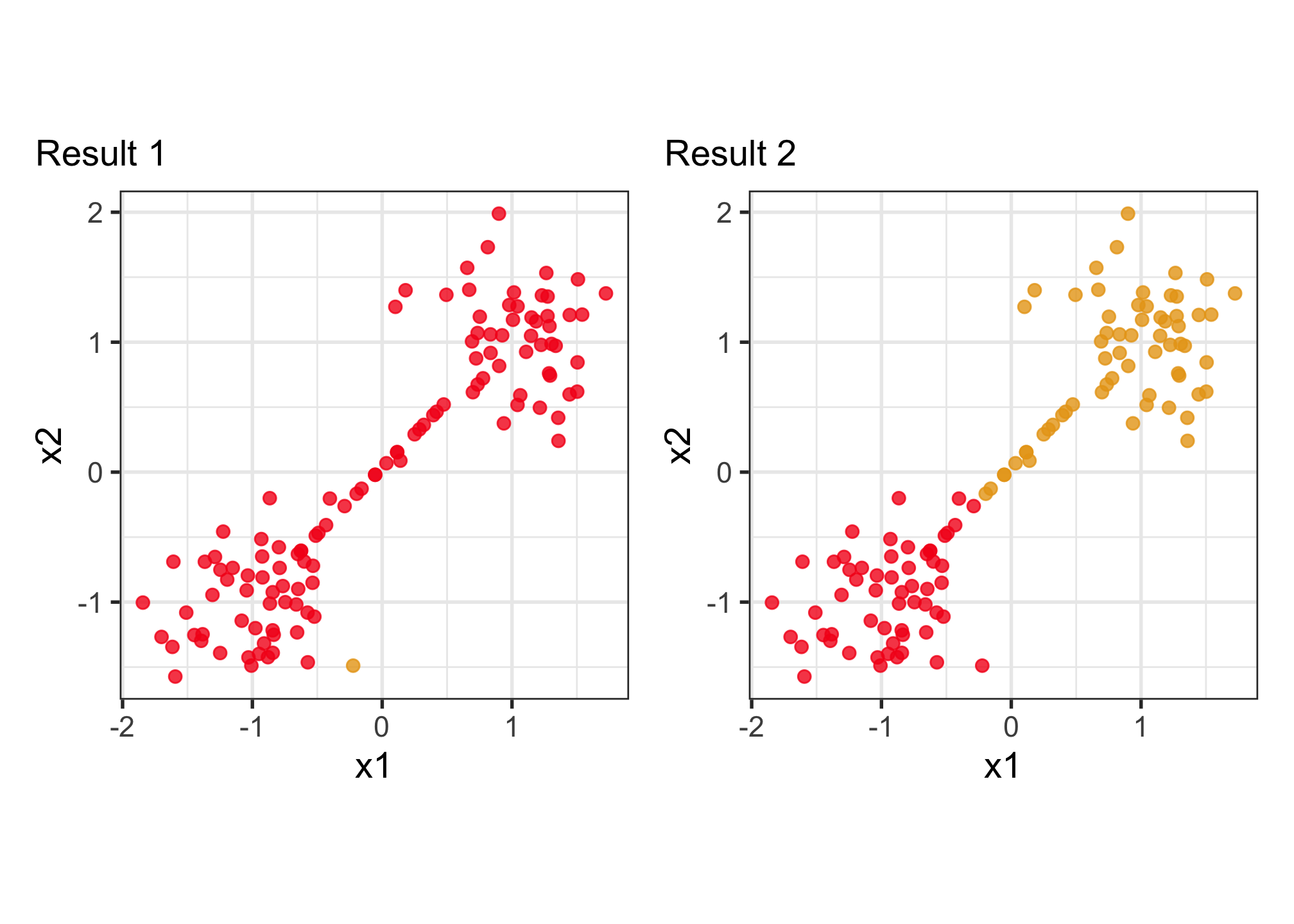
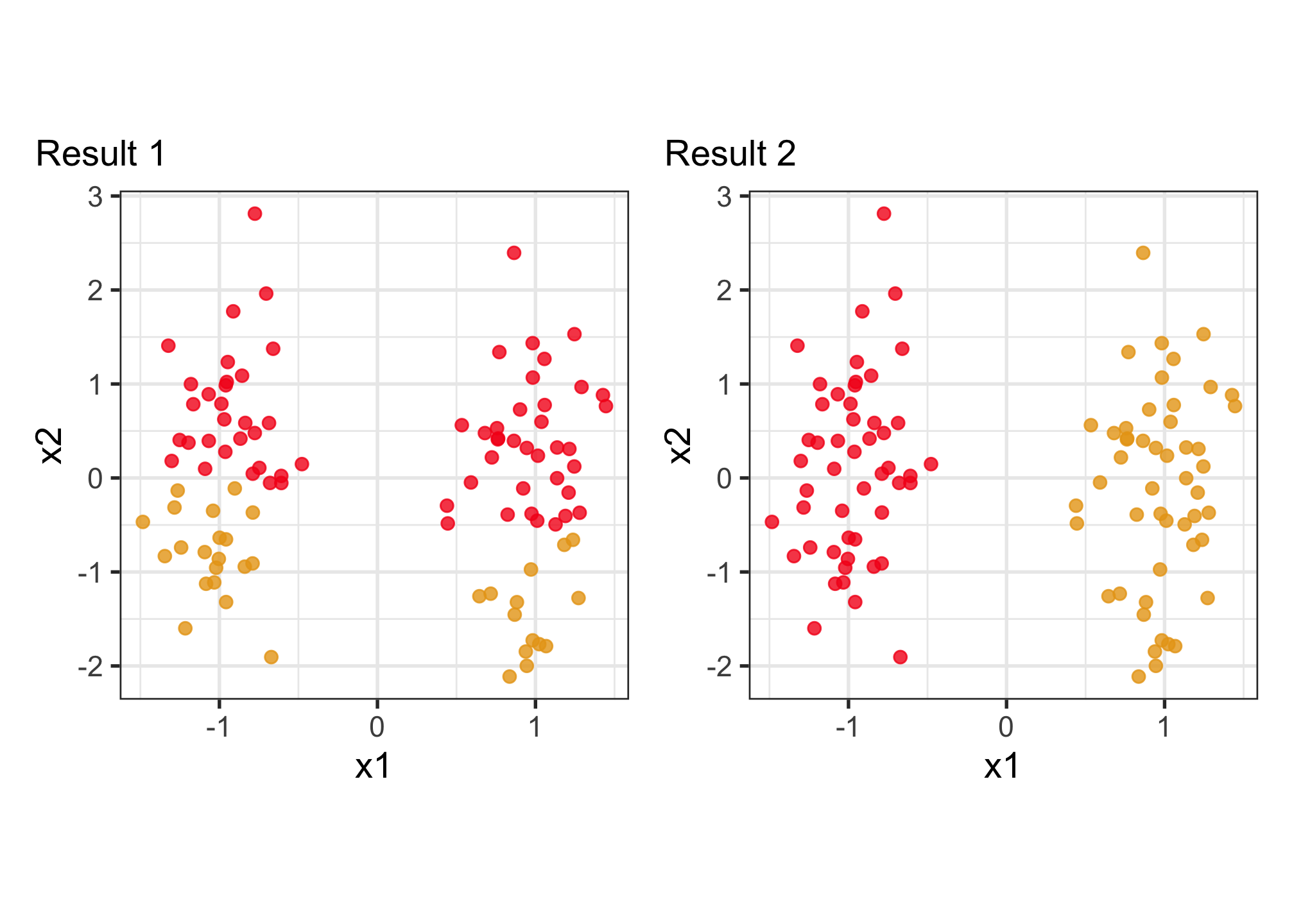
To decide on a best result, you need to see how it divides the data into clusters. The cluster statistics, like dendrogram, or cluster summaries, or gap statistics might all look good but the result is bad. You need to see the model in the data space!
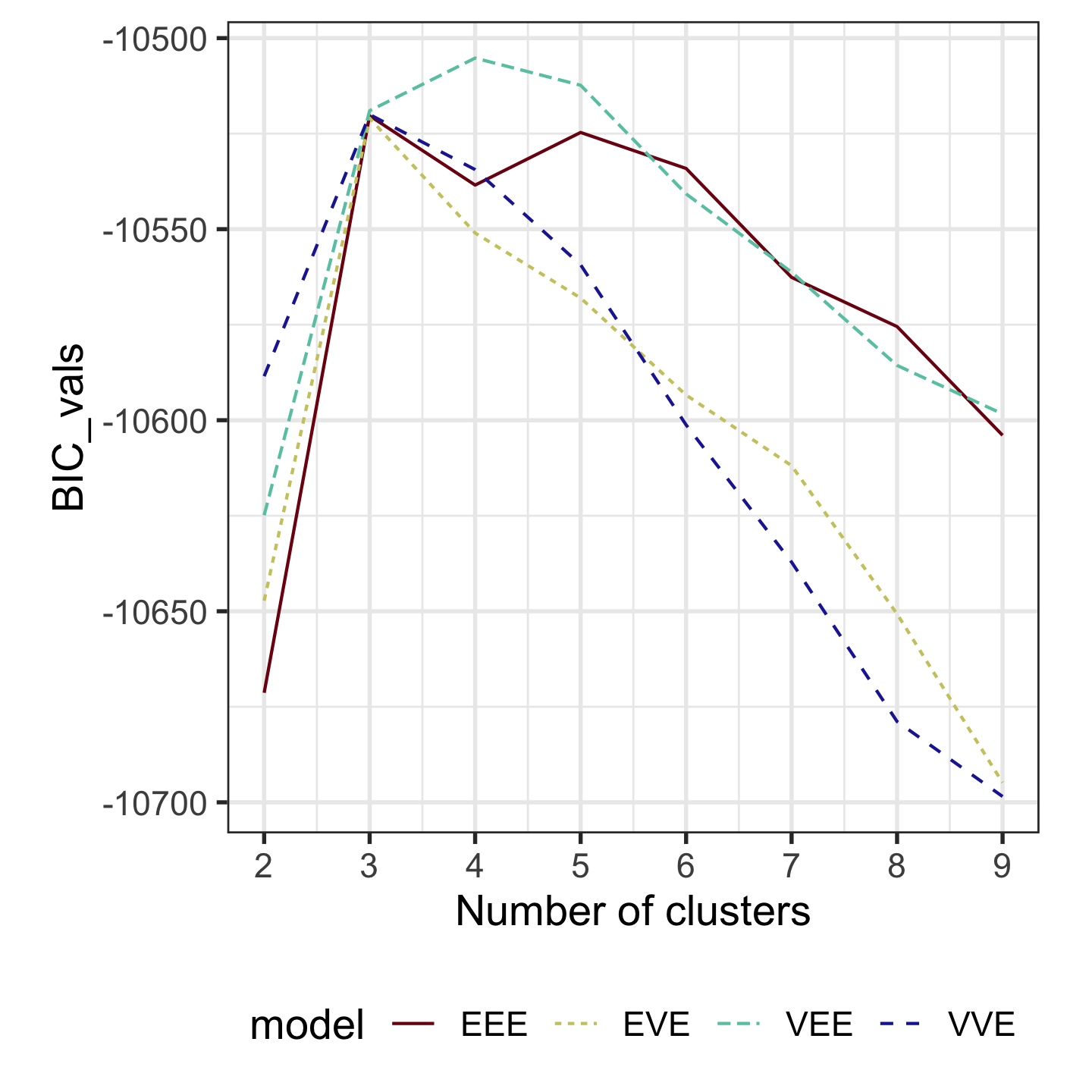
Model-based clustering (2/3)
Clustering this data. What do you expect?
Can we assume the shape of the clusters is elliptical?
Model-based clustering (3/3)
Four-cluster VEE
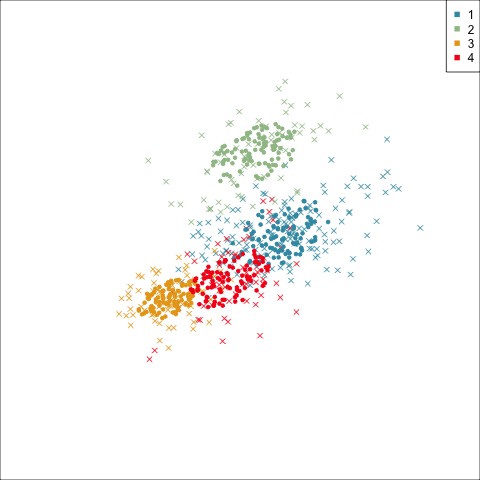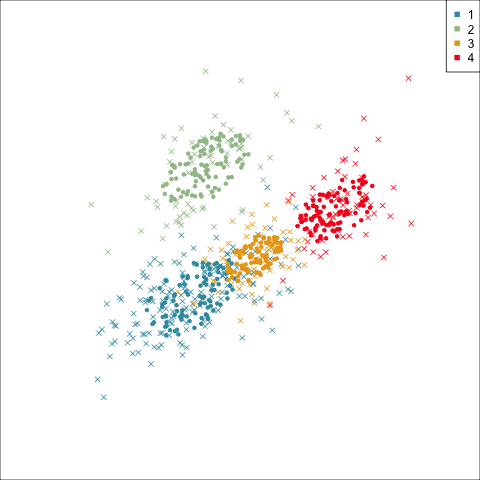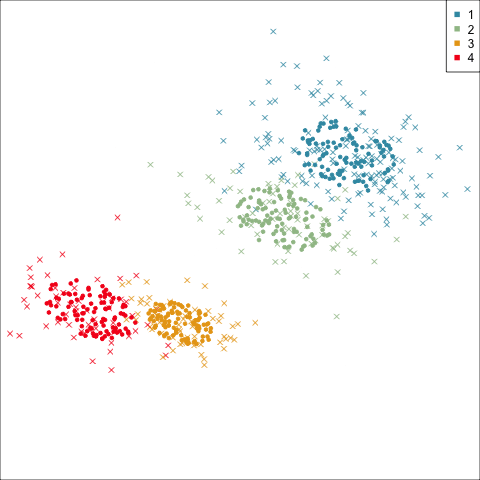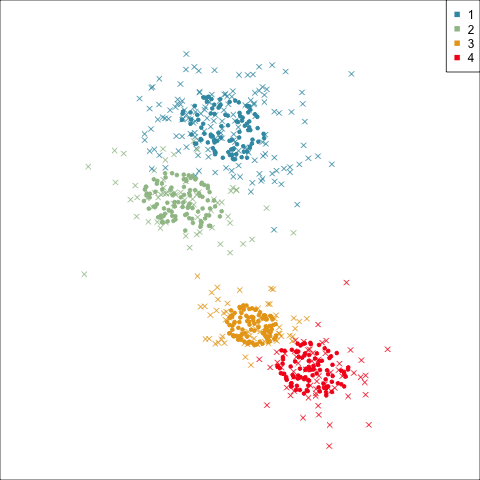
Three-cluster EEE
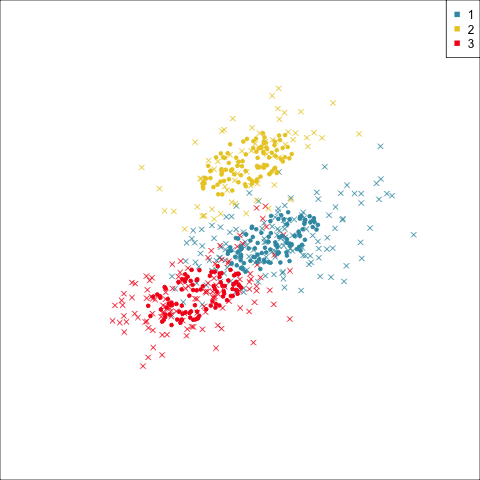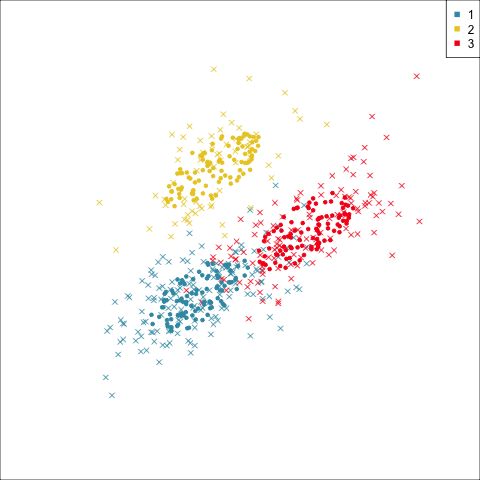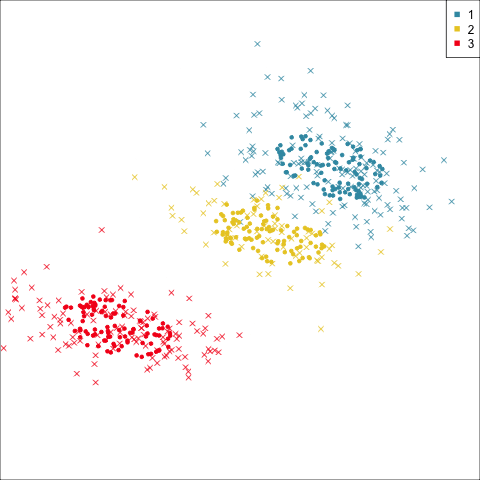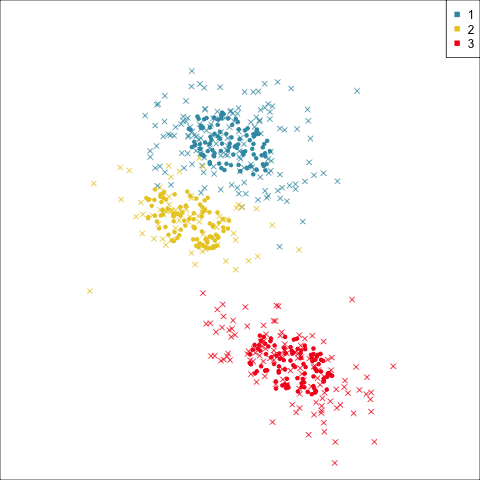
Models (ellipses) are overlaid on the data. Which is the best fit?
How do you draw ellipses in high-d?
Extract the estimated model parameters
p_mc <- Mclust(
p_tidy[,2:5],
G=3,
modelNames = "EEE")
p_mc$parameters$mean [,1] [,2] [,3]
bl 39 48 49
bd 18 15 18
fl 190 217 196
bm 3693 5076 3754p_mc$parameters$variance$sigma[,,1] bl bd fl bm
bl 8.4 1.6 8.3 755
bd 1.6 1.2 3.5 318
fl 8.3 3.5 42.5 1751
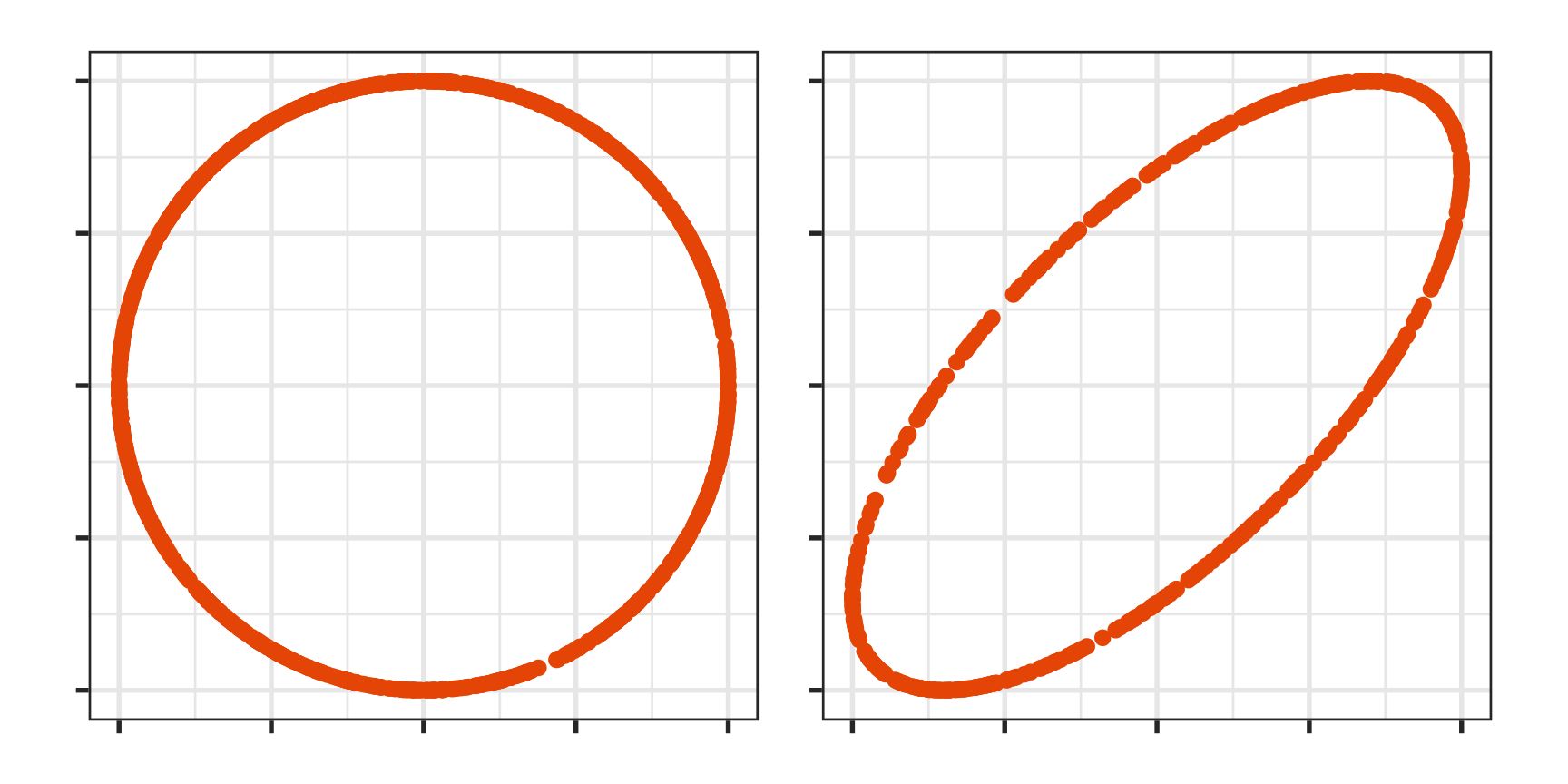
bm 754.7 318.4 1751.2 211467Generate data that represents the ellipse(s) to overlay on the data.
p_mce <- mc_ellipse(p_mc)- Sample points uniformly on a pD sphere
- Transform into an ellipse using the inverse variance-covariance matrix
Example: Linear DA
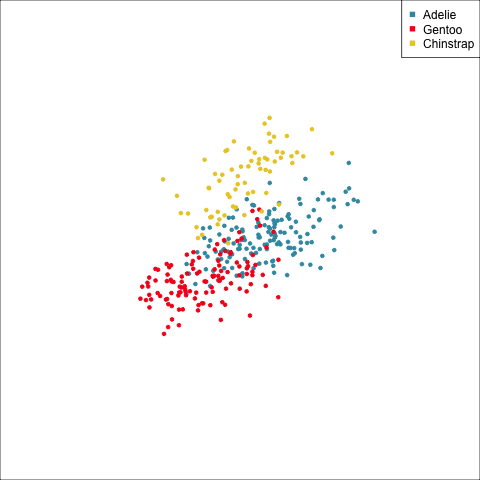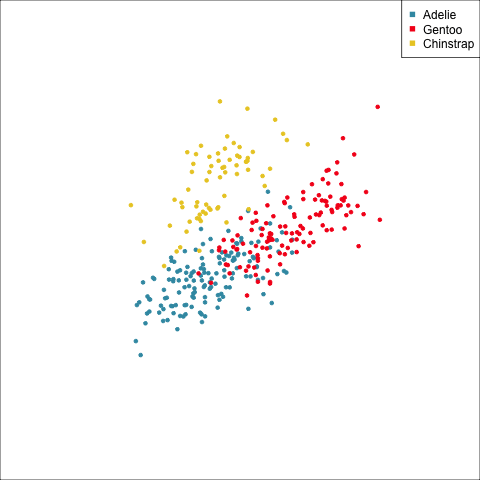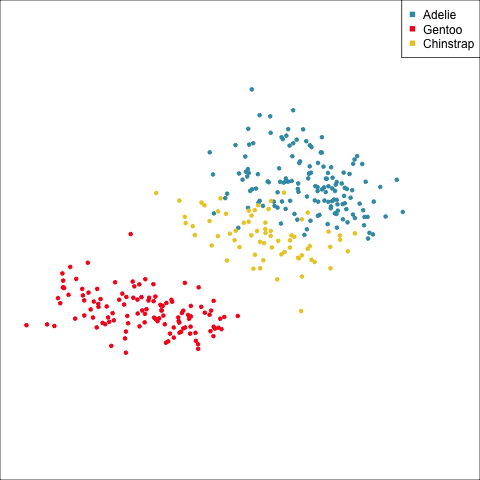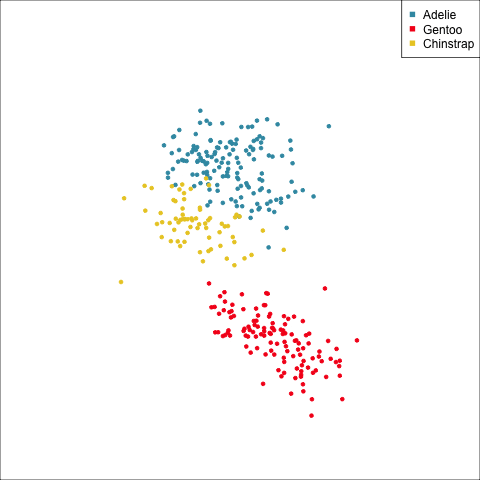
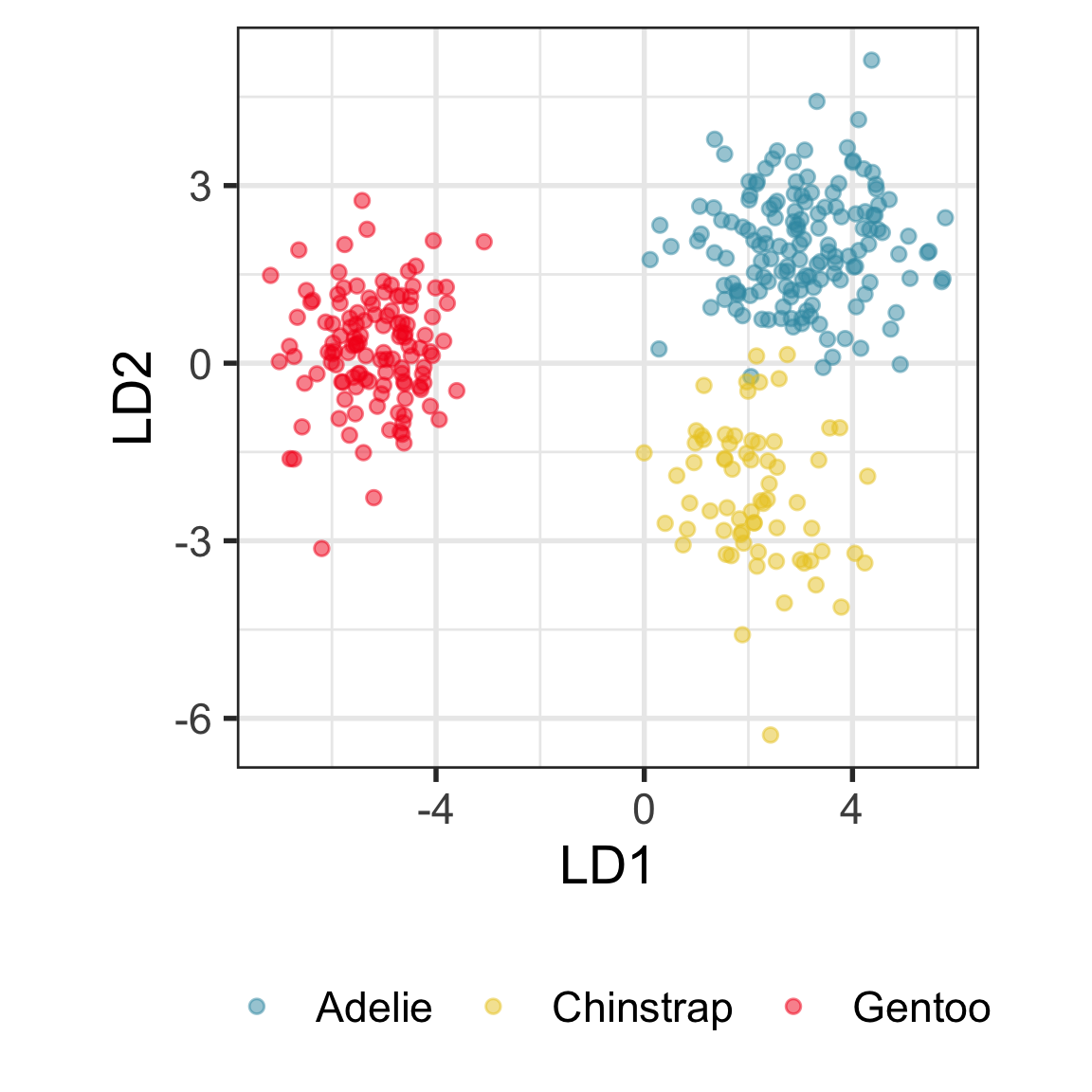
Linear discriminant analysis is the ideal classifier for this data.
Random forests (2/2)
The votes matrix can be considered to be predictive probabilities, where the values for each observation sum to 1. With 3 classes it is a 2D triangle. For 4 or more classes it is a simplex and can be examined in a tour.
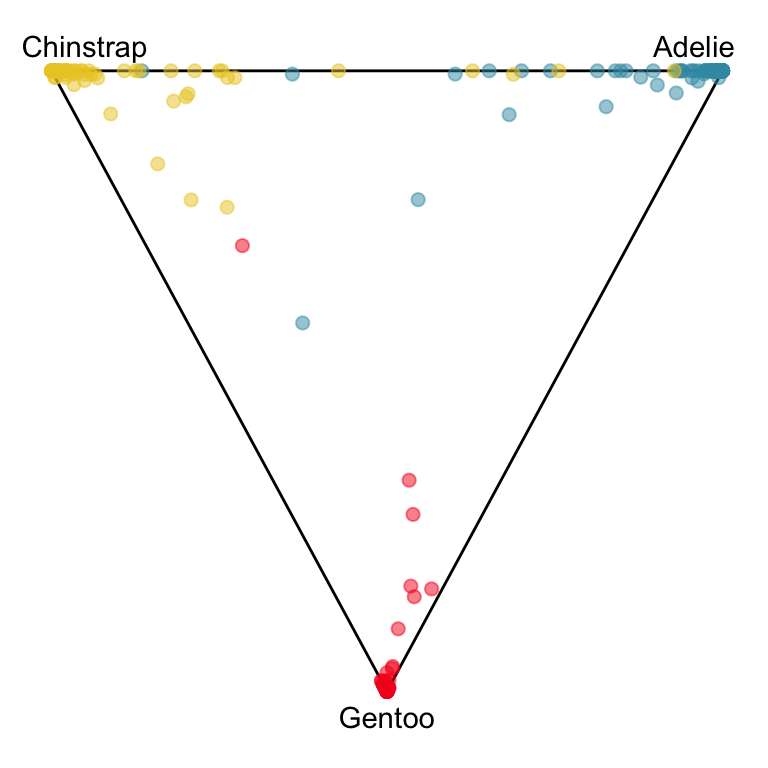
Votes matrix for bushfire model fit
Code
# Create votes matrix data
bushfires_rf_votes <- bushfires_rf$votes %>%
as_tibble() %>%
mutate(cause = bushfires_sub$cause)
# Project 4D into 3D
proj <- t(geozoo::f_helmert(4)[-1,])
b_rf_v_p <- as.matrix(bushfires_rf_votes[,1:4]) %*% proj
colnames(b_rf_v_p) <- c("x1", "x2", "x3")
b_rf_v_p <- b_rf_v_p %>%
as.data.frame() %>%
mutate(cause = bushfires_sub$cause)
# Add simplex
simp <- simplex(p=3)
sp <- data.frame(simp$points)
colnames(sp) <- c("x1", "x2", "x3")
sp$cause = ""
b_rf_v_p_s <- bind_rows(sp, b_rf_v_p) %>%
mutate(cause = factor(cause))
labels <- c("accident" , "arson",
"burning_off", "lightning",
rep("", nrow(b_rf_v_p)))
animate_xy(b_rf_v_p_s[,1:3], col = b_rf_v_p_s$cause,
axes = "off", half_range = 1.3,
edges = as.matrix(simp$edges),
obs_labels = labels)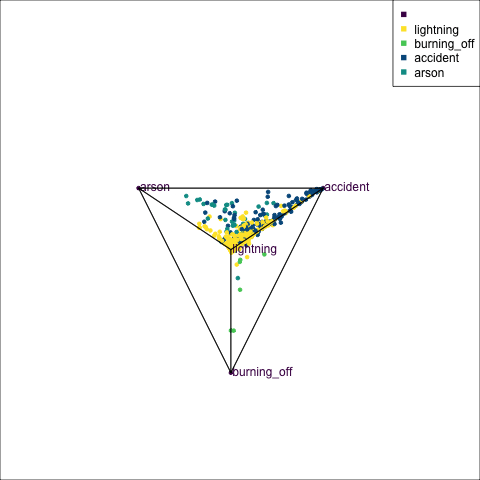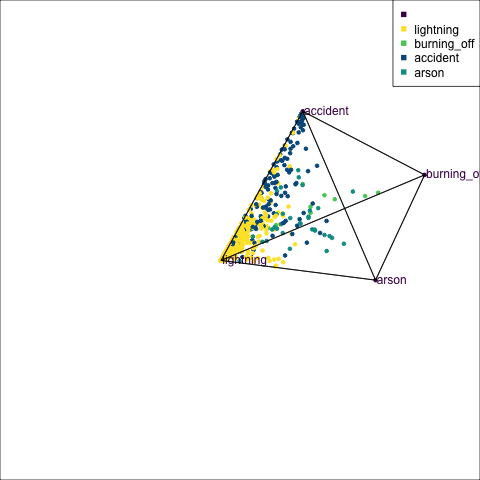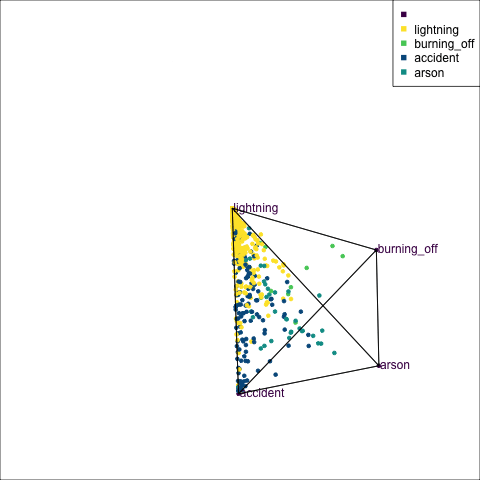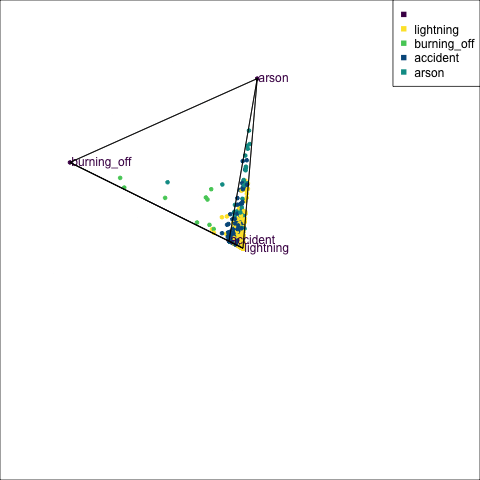
Cautions about high-dimensions
Space is big.
What might appear to be structure is only sampling variability.
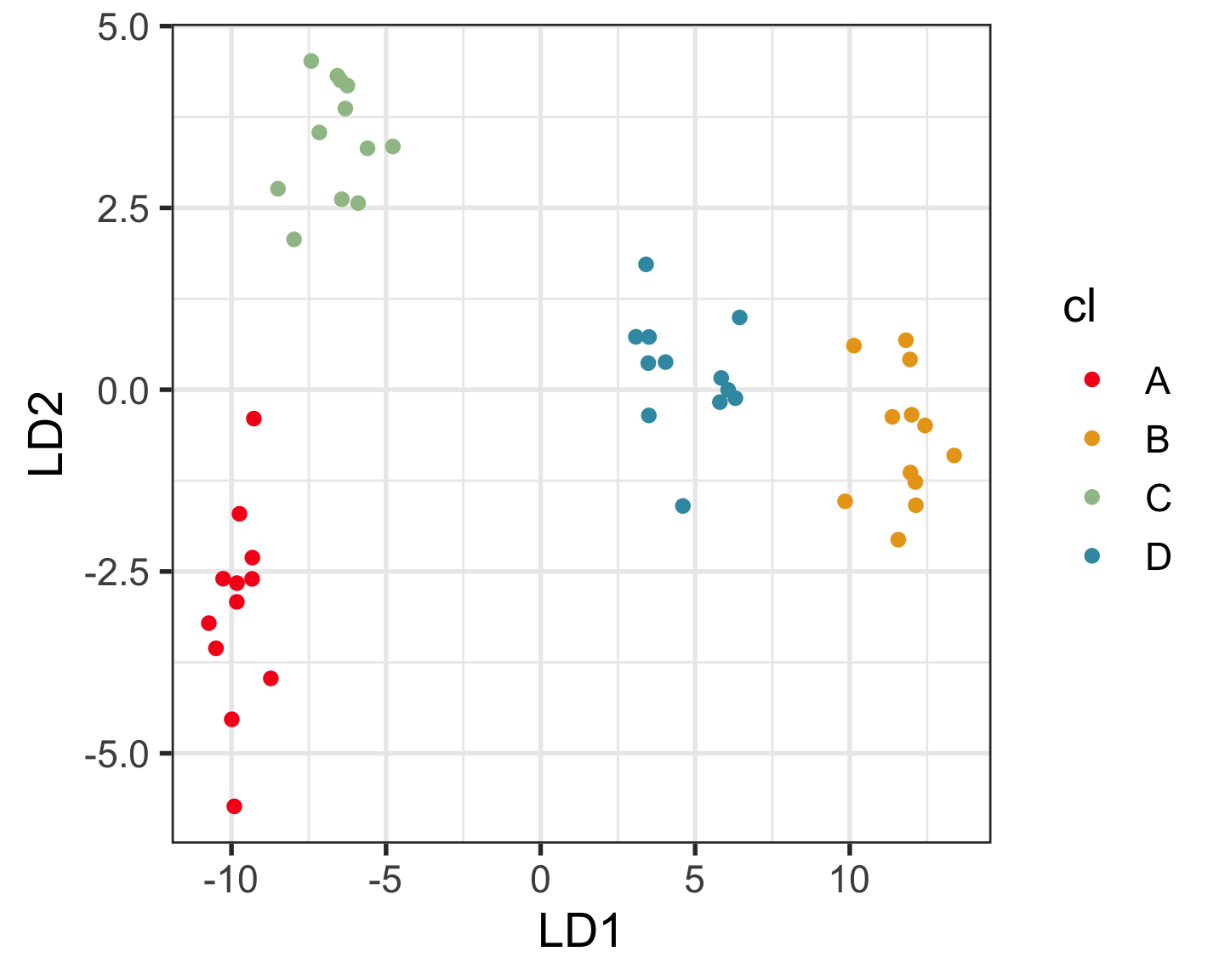
Permutation is your friend, for high-dimensional data analysis.
Permute the class labels.
set.seed(951)
ws <- w |>
mutate(cl = sample(cl))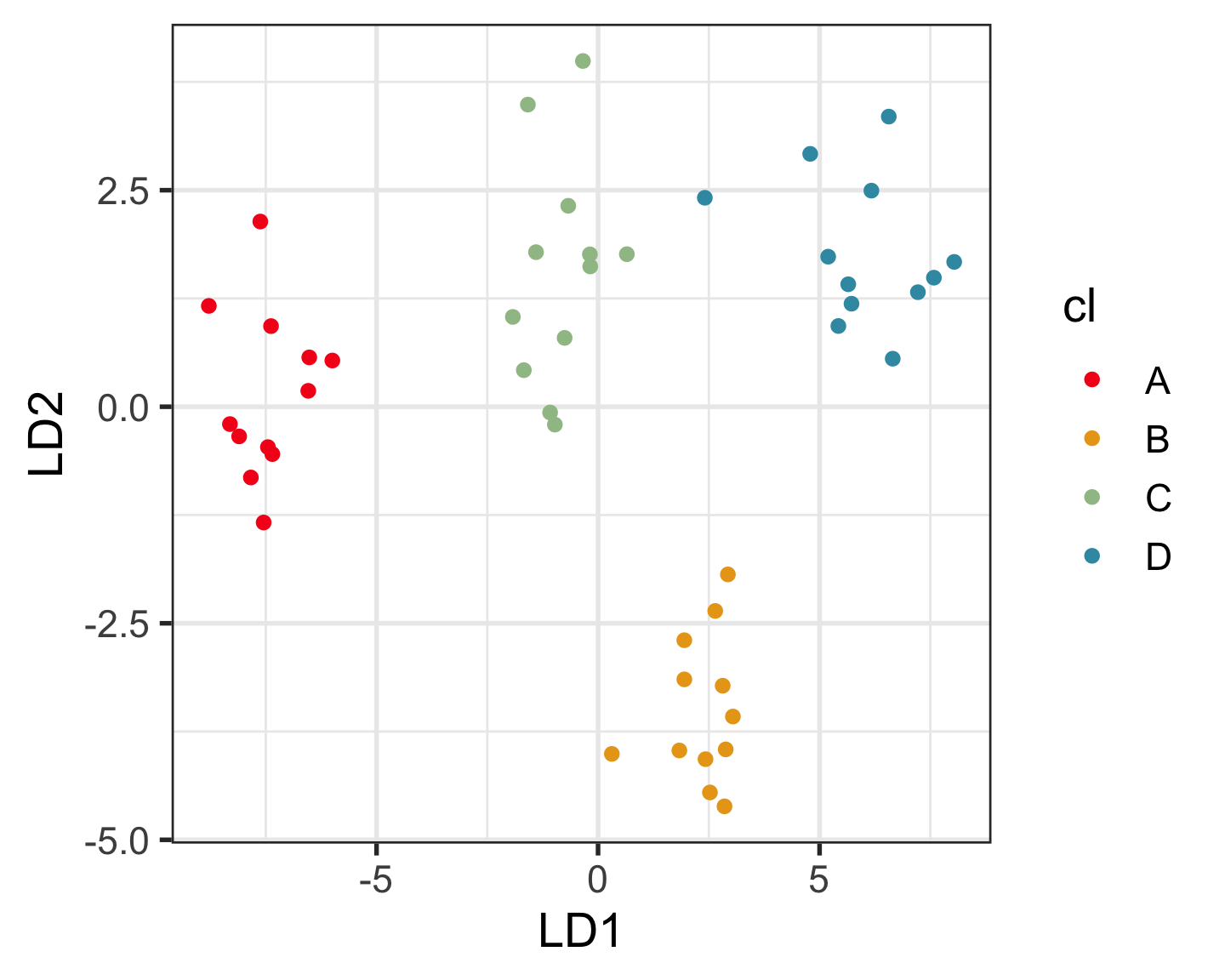
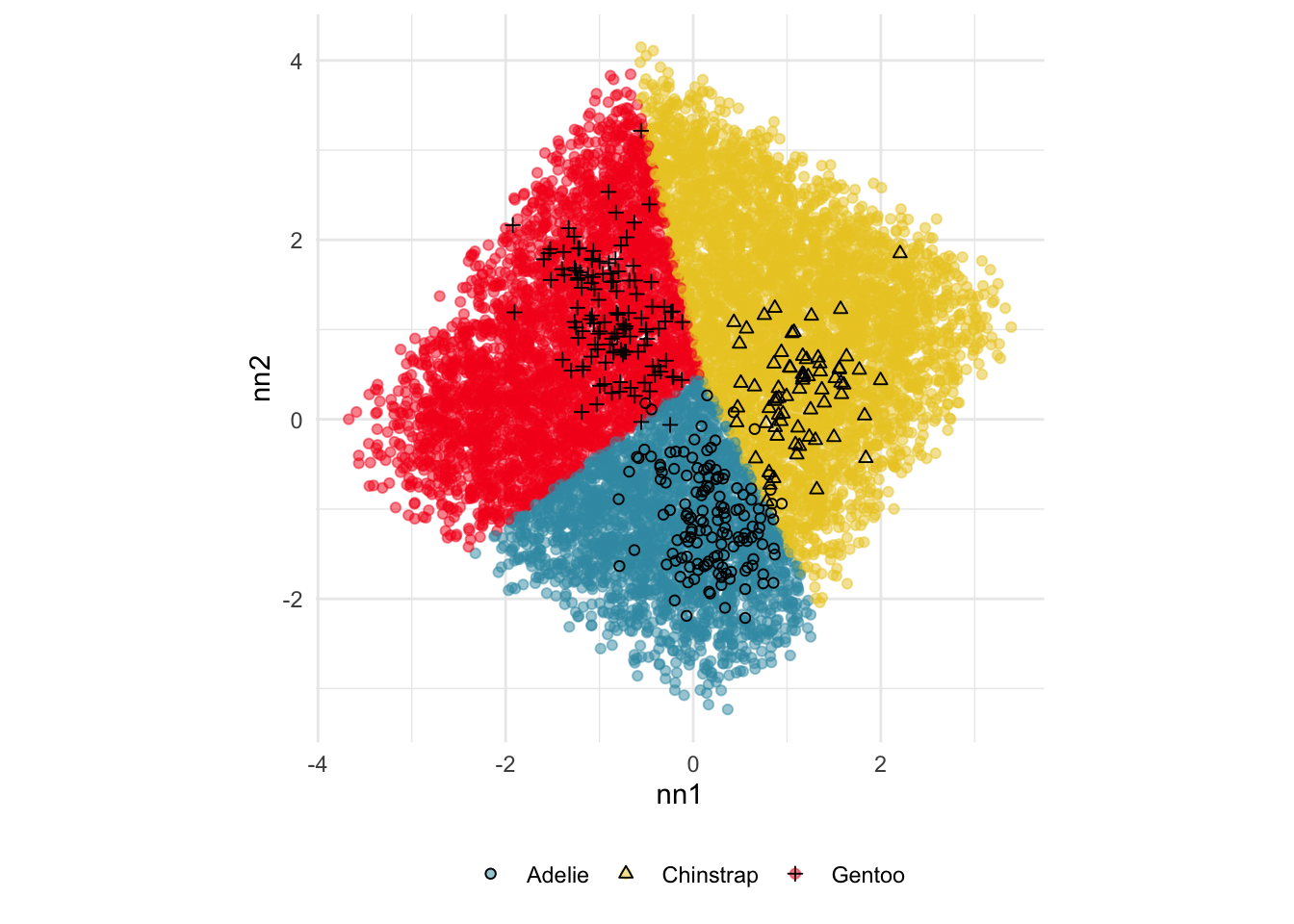
Other compelling pursuits
Explore and compare the boundaries of different models using the slice tour.

Dissect and explore the operation of a neural network.
Where to learn more
All of the material presented today comes from
Cook and Laa (2024) Interactively exploring high-dimensional data and models in R
Software:
![]()
![]() \(~~\)
\(~~\)  \(~~\)
\(~~\) ![]() \(~~\)
\(~~\) ![]() \(~~\)
\(~~\) 

End of session 2

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.